경제통계 공부시 다뤘던 R프로그램에 대해 정리한 내용입니다.
완전 기본적인 내용으로 부족한 부분이 많지만, 입문자들이 보기 편리할 것 같아 공유합니다.
R프로그램 (1~4)
.q() : R프로그램 종료
| 저장 | a <- 1 | b = 2 | c <- 3 | d <- 3.5 |
| 입력 | a | b | c | d |
| 출력값 | 1 | 2 | 3 | 3.5 |
| 입력 | a + b | a + b + c | 4 / b | 5 * c |
| 출력값 | 3 | 6 | 2 | 15 |
변수에 여러 값을 저장하는 방법
var1 <- c(1, 2, 5, 7, 8) : c안의 값 나열→ var1 입력시 [ 1 2 5 7 8 ] 출력
var2 <- c(1:5) : 1부터 5까지 나열 → var2 입력시 [ 1 2 3 4 5 ] 출력
var3 <- seq(1, 5) : 1부터 5까지 나열 → var3 입력시 [ 1 2 3 4 5 ] 출력
var4 <- seq(1, 10, by=2) : 1부터 2씩 증가하여 10까지 나열 → var4 입력시 [ 1 3 5 7 9 ] 출력
var<- seq(1, 10, by=3) : 1부터 3씩 증가하여 10까지 나열 → var 입력시 [ 1 4 7 10 ] 출력
var1 + 3 : 각 var1값에 3씩 추가됨 → 바로 [ 4, 5, 8, 10, 11] 출력
str1 <-“a” : 문구 저장시 무조건 “ “ 표시 해줄 것 → str1 입력시 [“a”] 출력
str2 <-“text” → str2 입력시 [“text”] 출력
str3 <-“Hello World!!” → str3 입력시 [“Hello Wold!!”] 출력
str4 <-“a”, “b”, “c” → str4 입력시 [“a” “b” “c”] 출력
str5 <-c(“Hello!”, “World”, “is”, “good!!!”) → str5 입력시 [“Hello!” “World” “is” “good!!!”] 출력
strl + 3 : 이항연산자에 수치가 아닌 연수라고 뜸 (오류!!)
x <-c(1, 2, 3) : 변수 만들기 → x 입력시 [1 2 3] 출력
→ mean(x) 입력시 [2] 출력 : 평균값
→ max(x) 입력시 [3] 출력 : x의 제일 큰 값
→ min(x) 입력시 [1] 출력 : x의 제일 작은 것
è paste() : 여러 문자들을 합쳐서 하나로 만드는 함수
è collapse =“,” : 단어들 합칠 때 쉼표 삽입
ex. paste(str5, collapse=”,”) → [“Hello!,World,is,good!!!”] 출력
paste(str5, collapse=” ”) → [“Hello! World is good!!!”] 출력(공백)
paste(str5) → [“Hello!” “World” “is” “good!!!”] 출력
<qplot>
install.packages(“ggplot2”) : 패키지 다운로드 library(ggplot2) : 패키지 불러오기
x <- c(“a”, “a”, “a”, “b”, “c”) : 변수 생성
qplot(x) : 빈도 막대 그래프 출력(qplot=변수)

qplot2(data=mpg, x=hwy) : ggplot2에 있는 mpg라는 데이터를 불러옴
x축에 hwy(자동차가 고속도로에서 기름 한 단위단 넣을 때 몇 마일을 주행하는지 = 변수:hwy)

qplot2(data=mpg, x=cty) : ?
qplot2(data=mpg, x=drv, y=hwy) : 산포도 생성

qplot(data=mpg, x=drv, y=hwy, geom=”line”) : 선그래프로 바뀜(이전에는 산포도-점)
qplot(data=mpg, x=drv, y=hwy, geom=”boxplot”) : 박스플롯으로 바뀜
qplot(data=mpg, x=drv, y=hwy, geom=”line”) : 선그래프로 바뀜(이전에는 산포도-점)
qplot(data=mpg, x=drv, y=hwy, geom=”boxplot”) : 박스플롯으로 바뀜


뒤에 colour=drv (따옴표x) : 박스플롯에 색상 추가
(drv값이 달라짐에 따라서 박스플롯의 색상이 바뀌도록)
R프로그램 (5)
- 데이터 프레임: 행과 열로 구성된 표처럼 생김
- 제약된 시간에서 가장 유용한 정보를 뽑아내는 작업은 빅데이터의 가장 핵심적인 관건이다.
R창→ 4명의 학생들이 영어, 수학 시험을 본다.
eng<-c(90, 80, 60, 70) : 영어 점수 변수 생성 → eng 입력시 [90 80 60 70] 출력
math<-c(50, 60, 100, 20) : 수학 점수 변수 생성 → math 입력시 [50, 60, 100, 20] 출력
df_midterm<-data.frame(eng, match)
: eng, match 데이터 프레임을 생성하고, 새로운 변수 df_midterm에 할당하기

→ df_midterm 입력시 이와 같이 출력
class<-c(1,1,2,2) : 데이터 프레임에 새로운 변수 추가하기(몇 반에 있는 학생인지 추가하기) – 변수 생성
df_midterm<-data.frame(eng, match, class) : 맨 끝에 새로운 변수만 추가(덮어쓰기)

→ df_midterm 입력시 이와 같이 출력
- 데이터프레임을 만드는 이유? R로 하여금 이 데이터를 분석하게 하기 위함(이제 데이터가 준비되었으므로 분석해야할 차례)
mean(df_midterm$eng) : $표시가 들어감으로써 df_midterm이라는 데이터프레임을 정의를 하고
프레임 안에 있는 eng라는 변수를 불러낸다 (mean이란? 괄호 안 변수의 평균값)

→ mean(df_midterm$eng) 입력시 [75] 출력
→ mean(df_midterm$math) 입력시 [57.5] 출력
df_midterm2<-data.frame(eng=c(90, 40, 20, 10), math=c(90, 100, 20, 80), class=c(1, 1, 2, 1)
:한번에 데이터프레임 불러옴 (만약 class=c(1,1,2,1,1)처럼 5명에 대한 정보면, 행의 개수와 달라서 오류)
R프로그램 (6) : 엑셀 파일을 R프로그램으로 불러오는 법
< readxl >
install.packages(“readxl”) : readxl이라는 패키지를 불러옴 > 서울 선택 > 부수적으로 필요한 패키지 자동 설치
library(readxl) : 패키지 불러오기(필수, 따옴표 필요x)
getwd(): 작업하고 있는 폴더의 경로를 알려주는 명령어(ex.”C:/Users/SSU/Documents”)
df_exam<-read_excel(“excel_exam.xlsx”) : 따옴표안에 파일명과 확장자까지 입력하여 엑셀 파일을 불러와서
변수 df_exam에 할당하는 작업
df_excel<-read_excel(“excel_exam.xlsx”, sheet=3) 엑셀의 3번째 시트 불러오기
mean(df_exam$math) : math 열에 있는 평균(총 21개 행 중에서 변수명을 제외한 20개 행의 평균)
mean(df_exam$science) : science 열에 있는 평균
df_exam<-read_excel(“excel_exam.xlsx”, col_name=F) : 첫번째 행을 변수명으로 인식하지 않도록 해주는 명령어
help read_excel = ?read_excel : read_excel이라는 명령어에 대한 설명서가 뜸
R프로그램 (7) : R프로그램으로 만드는 그래프
<ggplot2>
install.packages(“ggplot2”) : ggplot2라는 패키지를 불러옴 > 서울 선택 > 부수적으로 필요한 패키지 자동 설치
- 산포도, 산점도, scatter plot
- ggplot2 먼저 배경이 되는 축을 선택한 다음 그래프 형태를 결정하고 부수적인 옵션을 추가
library(ggplot2) : 패키지 불러오기(따옴표 필요x)
내장되어 있는 mpg라는 데이터를 활용, 가로축은 displ (배기량), 세로축은 hwp (고속도로 연비)
ggplot(data=mpg, aes(x=displ, y=hwy)) : 그래프 기본 배경 불러오기 (aes:그래프를 위한 배경 설정 명령어)

→ 그래프 배경
ggplot(data=mpg, aes(x=displ, y=hwy))+geom_pint() : 모든 데이터를 다 표시해라(산점도를 그려라)

→ 관측값을 점으로 표시함
이를 통해 배기량이 큰 자동차일수록 고속도로 연비가 낮아지는 경향이 있는 것을 파악할 수 있다.
ggplot(data=mpg, aes(x=displ, y=hwy))+geom_pint()+xlim(3,6) : x축의 범위를 3에서 6까지 한정하겠다

ggplot(data=mpg, aes(x=displ, y=hwy))+geom_pint()+xlim(3,6)+ylim(10,30)
: y축의 범위를 10에서 30까지 한정하겠다
R프로그램 (8) : 데이터 가공
<dplyr>
install.packages(“dplyr”) : dplyr이라는 패키지를 불러옴 > 서울 선택 > 부수적으로 필요한 패키지 자동 설치
- filter() : 행 추출 - select() : 열(변수) 추출 - arrange() : 정렬
- mutate() : 변수 추가 - summarise() : 통계치 산출 - group_by() : 집단별로 나누기
- left_join() : 데이터 합치기 (열) - bind_rows() : 데이터 합치기 (행)
exam<-read.csv(“csv_exam.csv”) : csv_exam이라는 csv파일 불러오기
library(dplyr) : 반드시 패키지를 한 번 불러와야 작동함
exam%>%filter(class==1) : exam을 정렬을 하는데 class가 1인 값만 출력한다(엑셀 필터 적용과 같음)

exam%>%filter(class!=4) : 1반 학생의 점수만 없애고 다른 반의 점수만 출력(1반만 제외)

exam%>%filter(math>50) : 수학점수가 50점 초과인 학생들만 출력

→전체 20명 중 10명만 출력 됨
exam%>%filter(math>=60) : 수학점수가 60점 이상인 학생들만 출력

exam%>%filter(math==1&math>=50) : 1반이면서 수학점수가 50점 이상인 학생들만 출력 →여러 조건 & (= 그리고)

exam%>%filter(math==2&english>=80) : 2반이면서 영어점수가 80점 이상인 학생들만 출력

exam%>%filter(math==2 | english>=80) : 2반이면서 영어점수가 80점 이상인 학생들만 출력 →여러 조건 | (=이거나)

exam%>%filter(class==1 | class==3 | class==5) : 1반, 3반, 5반 학생 출력
exam%>%filter(class %in% c(1,3,5)) : 1반, 3반, 5반 학생 출력(위와 같음)
class1<-exam%>%filter(class==1) : class1에 1반의 데이터 입력(데이터프레임 형식으로 들어간 것)

→class1 입력시 이와 같이 출력 / mean(class1$math) → [46.25] 출력
exam%>%select(math) : 특정 math열만 추출

exam%>%select(english) : 특정 english열만 추출

exam%>%select(class, math, english) : class, math, english열만 추출

exam%>%select(-english) : english열만 제외하고 추출
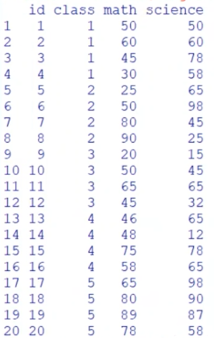
→ math열도 추가로 제외하고 싶다면? -math, -english
exam %>%filter(class==1) %>%select(english) : 1반 학생의 영어 점수만 →filter와 select 함께 이용하기

exam %>%
+filter(class==1) →위와 같은 결과가 나옴 / 보기 편리하게 행 구분이 가능

exam %>%select(id,math) %>%head : 전체 20명에 대한 id, math 데이터 중 처음 6개만 출력

exam %>%select(id,math) %>%head(10) : 전체 20명에 대한 id, math 데이터 중 처음 10개만 출력

exam %>%arrange(math) : 수학 점수를 기준으로 가장 낮은 점수부터 오름차순으로 정렬
exam %>%arrange(desc(math)) : 수학 점수를 기준으로 가장 높은 점수부터 내림차순으로 정렬
exam %>%arrange(class, math) : 반 정렬 → 반 안에서 수학 점수 정렬

exam %>%mutate(total=math+English+science) : 새로운 변수(열)를 추가하는 명령문 mutate →total이라는 변수 추가
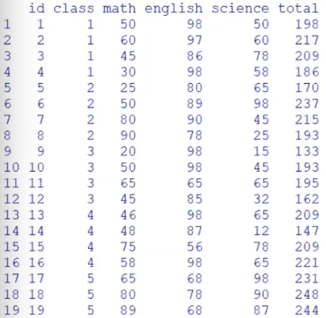
→새로운 total 열 생성
exam %>%mutate(total=math+English+science, mean=(math+english+science)/3)

→total, mean 열 생성
exam %>%summarise(mean_math=mean(math) : mean_math라는 변수에 수학점수의 평균=mean(math)을 산출
exam %>%group_by(class) %>%summarise(mean_math=mean(math))
: group by→1반부터 5반까지 그룹화 / 각 그룹(반)의 mean_math 산출
→total, mean 열 생성
|
> summarise(변수명=명령문) →저장
> 변수명 →입력 변수명 명령값(산출값) →변수명~명령값 출력 |

exam %>%group_by(class)
%>%summarise(mean_math=mean(math), sum_math=sum(math), median_math=median(math), n=n())

n은 단지 행 갯수를 세어주는 것이므로 별도의 변수명은 필요x
test1 <- data.frame(id=c(1,2,3,4,5), midterm=c(60,80,70,90,85))
test2 <- data.frame(id=c(1,2,3,4,5), midterm=c(70,83,65,95,80))

→위에서 만든 데이터프레임 출력
total <- left_join(test1, test2, by=”id”) : id를 기준으로 합친 다음, total이라는 새로운 데이터프레임에 넣어주는 것

→x=1, y=2(id기준으로 왼쪽부터 test1, 2)
test2 <- data.frame(id=c(1,2,3,4,5), final=c(70,83,65,95,80)): test2 다시 정의
total <- left_join(test1, test2, by=”id”) : id를 기준으로

→ test2에 넣은 final이 추가됨
name <- data.frame(class=c(1,2,3,4,5), teacher=c(“kim”,”lee”, “park”, “choi”, “jung”))

exam_new <- left_join(exam, name, by=”class”) : class를 (우측)기준으로 왼쪽부터 exam, name 삽입
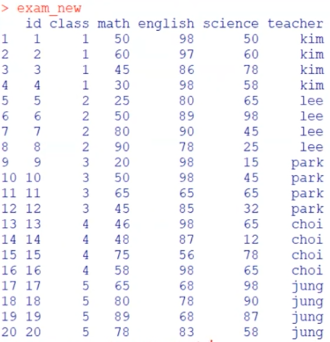
group_a <- data.frame(id=c(1,2,3,4,5), test=c(60,80,70,90,85))
group_b <- data.frame(id=c(6,7,8,9,10), test=c(70,83,65,95,100))
group_all <-bind_rows(group_a, group_b) : 각 데이터 프레임을 하나의 데이터 프레임으로

'A lot > 경제' 카테고리의 다른 글
| [경제신문] 한국경제(2022.09.13) - DX혁명/내부자사전공시제도/투기성매매,한미금리역전 (0) | 2022.09.15 |
|---|---|
| [재무관리] 기업평가 레버리지의 종류와 개념 (0) | 2022.06.24 |
| [재무관리] 기업평가 재무비율 공식 정리 (0) | 2022.06.24 |
| [금융] 간접금융, 직접금융 차이/은행업의 본질/은행의 경영관리 및 역할 (0) | 2022.06.07 |




댓글